From Threads to LLVM Coroutines: A Guided Tour
One of the most fascinating parts of modern compiler design is how high-level constructs are lowered into raw intermediate representations. Coroutines in C++20 are a prime example: they look like structured concurrency in source code, but when you peek under the hood with Clang and LLVM you see a machinery of intrinsics, frames, and transformation passes.
In this post I’ll walk through a practical journey: starting with a simple multi-threaded program, refactoring it into coroutines, then inspecting the LLVM IR as the compiler translates cooperative suspension points into explicit state machines.
Threads vs Coroutines
- Threads (e.g.
std::jthread) are scheduled by the OS. They run concurrently, with real preemption, context switches, and synchronization primitives like mutexes. - Coroutines are cooperative. They suspend and resume explicitly. There’s no magic preemption — instead, you need an executor (like a thread-pool) to provide concurrency.
That difference shapes how they lower into LLVM IR: threads don’t introduce new
IR intrinsics, but coroutines do — special calls like llvm.coro.id,
llvm.coro.suspend, llvm.coro.end.
Baseline: Multi-Threaded Code
Let’s start with a simple program that launches four threads, each summing a chunk of work:
#include <vector>
#include <thread>
#include <mutex>
#include <iostream>
int main() {
const int N = 4;
const int per = 100000;
std::vector<std::jthread> ts;
long long total = 0;
std::mutex m;
for (int i = 0; i < N; ++i) {
ts.emplace_back([&, i]{
long long local = 0;
for (int k = 0; k < per; ++k) local += (i + k) % 97;
std::scoped_lock lk(m);
total += local;
});
}
std::cout << total << "\n";
}
Straightforward: spin up threads, compute partial results, merge under a mutex.
Refactor: Coroutine Style
Here’s the coroutine version with a minimal task
// after_coroutines.cpp
#include <coroutine>
#include <iostream>
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <optional>
#include <functional>
// ... thread_pool definition omitted for brevity ...
template<class T>
struct task {
struct promise_type {
std::optional<T> value;
task get_return_object() {
return task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void unhandled_exception() {}
void return_value(T v) { value = std::move(v); }
};
std::coroutine_handle<promise_type> h;
~task(){ if (h) h.destroy(); }
T get() { h.resume(); return *h.promise().value; }
};
struct schedule_on_pool {
thread_pool* pool;
bool await_ready() const noexcept { return false; }
void await_suspend(std::coroutine_handle<> h) const {
pool->post([h]{ h.resume(); });
}
void await_resume() const noexcept {}
};
task<long long> worker(int i, int per, thread_pool& pool) {
co_await schedule_on_pool{&pool};
long long local = 0;
for (int k = 0; k < per; ++k) local += (i + k) % 97;
co_return local;
}
task<long long> run_all(int N, int per, thread_pool& pool) {
long long total = 0;
std::vector<task<long long>> tasks;
for (int i = 0; i < N; ++i) tasks.push_back(worker(i, per, pool));
for (auto& t : tasks) total += co_await t;
co_return total;
}
int main() {
thread_pool pool{4};
auto t = run_all(4, 100000, pool);
std::cout << t.get() << "\n";
}
Notice: the logic is the same (“divide work, sum results”), but written in coroutine style.
Inspecting LLVM IR
Here’s where it gets interesting. Let’s compile the coroutine version to LLVM IR with passes disabled:
clang++ -std=c++20 -stdlib=libc++ -O0 \
-S -emit-llvm -Xclang -disable-llvm-passes \
after_coroutines.cpp -o after_coroutines.raw.ll
When you open after after_coroutines.raw.ll you should see intrinsics like:
; identify this function as a coroutine and create its frame
%id = call token @llvm.coro.id(i32 0, ptr null, ptr null, ptr null)
; materialize the coroutine frame (opaque i8* now, real struct later)
%frame = call ptr @llvm.coro.begin(token %id, ptr %alloc)
... // code omitted.
br i1 %suspend, label %suspend.bb, label %resume.bb
... // code omitted.
call i1 @llvm.coro.suspend(...)
...
call void @llvm.coro.end(...)
These intrinsics are compiler “markers” for coroutine boundaries — not real instructions, but hooks the LLVM optimizer understands.
If you like to go into details, here’s what it means …
@llvm.coro.idtags the function as a coroutines and collects ABI bits@llvm.coro.beginreturns a pointer to the frame (the heap/stack object that holds locals, promises)- The promise object is a field inside that frame.
Let’s take a moment and follow how run_all is being translated and eventually lowered into LLVM IR.
define void @_Z7run_alliiR11thread_pool(...) {
...
%26 = call token @llvm.coro.id(i32 16, ptr %25, ptr null, ptr null)
%27 = call i1 @llvm.coro.alloc(token %26)
...
; state is saved, s.t. it can resume later
%40 = call token @llvm.coro.save(ptr null)
call void @llvm.coro.await.suspend.void(ptr %13, ptr %33, ptr @_Z7run_alliiR11thread_pool.__await_suspend_wrapper__init) #2
; point of suspension.
%41 = call i8 @llvm.coro.suspend(token %40, i1 false)
; Branch to the suspend or resume continuation blocks.
switch i8 %41, label %119 [
i8 0, label %43 ; parked at final suspend, awaiting destroy
i8 1, label %42
]
...
%120 = call i1 @llvm.coro.end(ptr null, i1 false, token none), !dbg !6579
ret void, !dbg !6579
What the above means:
@llvm.coro.savecaptures a continuation point@llvm.coro.suspendmarks a suspension; the value it return routes control to: (a) the suspend path (i.e., returning to the caller), (b) the resume path (whenXX.resume()is called), or © cleanup (on destruction or stack unwind).
What this means …
@llvm.coro.endmarks termination of the coroutine’s lifetime.@llvm.coro.freeyields the address that should be deallocated (passes inject the actual call).
Transforming with opt
Next, run the coroutine pipeline:
opt -passes='coro-early,coro-elide,coro-split,coro-cleanup' \
after_coroutines.raw.ll -S -o after_coroutines.lowered.ll
Now if you inspect after_coroutines.lowered.ll, you’ll see:
- A real frame struct (e.g.,
%worker.Frame = type { … }) replacing the opaque pointer. - Separate resume / destroy entry points; switch dispatch based on a state field.
malloc/newandfree/deleteinserted (or elided if proven unnecessary).- Most
@llvm.coro.*calls removed — replaced by explicit control flow + data.
This shows the two-phase lowering:
- Clang inserts intrinsics into IR.
- LLVM passes expand them into concrete control flow and data structures.
Lessons Learned
- Coroutines aren’t threads. They give you structure, not pre-emption. To actually run concurrently, you need an executor.
- Two stages of lowering: (a) Clang emits co-routine intrinsics, (b) LLVM passes re-write them into explicit IR.
- The raw LLVM IR (e.g., switch “-disable-llvm-passes”) reveals the
llvm.coro.*intrinsics. After running coroutine passes, those intrinsics disappear into a state machine (I’ll describe state machines later). - Seeing both stages (before and after
opt) is invaluable to understand how high-level constructs map down to lower-level mechanics. - Why you might not see intrinsics. By default, Clang may run some passes automatically.
Use
-Xclang -disable-llvm-passesto get the raw IR. - This exercise also teaches a broader lesson: “what you write” in C++ is only the starting point; compilers are constantly rewriting, reorganizing, and optimizing it.
Custom Awaiter
So far we’ve seen how co_await std::suspend_always{} lowers into
llvm.coro.save and llvm.coro.suspend. But coroutines get really interesting
when you use custom awaiters that override the three key hooks:
- await_ready() → Should we suspend?
- await_suspend(handle) → What to do at the suspension point?
- await_resume() → What to produce when resuming?
Let’s try one
A simple custom awaiter — to get started.
#include <coroutine>
#include <cstdio>
struct print_awaiter {
bool await_ready() const noexcept {
std::puts("await_ready → false");
return false; // force suspension
}
void await_suspend(std::coroutine_handle<>) const noexcept {
std::puts("await_suspend called");
// (could enqueue into an event loop instead of just printing)
}
int await_resume() const noexcept {
std::puts("await_resume called");
return 7; // produce a value for the coroutine
}
};
struct task {
struct promise_type {
int value{};
void unhandled_exception() {}
task get_return_object() {
return task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() noexcept { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_value(int v) noexcept { value = v; }
void unhandled_exception() { std::terminate(); }
};
std::coroutine_handle<promise_type> h;
~task(){ if (h) h.destroy(); }
int run() {
h.resume();
h.resume();
return h.promise().value;
}
};
task foo() {
int x = co_await print_awaiter{};
co_return x + 1;
}
int main() {
task t = foo();
std::printf("result = %d\n", t.run());
}
As before, remember to disable the LLVM passes to see the simplified IR and here’s what it looks like (note i’ve simplified the variable names so that we can follow semantically instead of variable names like %30, %31 etc :
; coroutine setup
%id = call token @llvm.coro.id(i32 0, ptr null, ptr null, ptr null)
%frame = call ptr @llvm.coro.begin(token %id, ptr null)
; construct awaiter on the stack
%awaiter = alloca %struct.print_awaiter, align 1
; call await_ready()
%ready = call zeroext i1 @_ZNK13print_awaiter11await_readyEv(ptr %awaiter)
; branch depending on ready?
br i1 %ready, label %resumeDirect, label %suspendPath
suspendPath:
; call await_suspend(handle)
call void @_ZNK13print_awaiter13await_suspendENSt3__18coroutine_handleIvEE(ptr %awaiter, ptr %coro.handle)
; then suspend!
%save = call token @llvm.coro.save(ptr null)
%susp = call i8 @llvm.coro.suspend(token %save, i1 false)
...
resumeDirect:
; call await_resume()
%val = call i32 @_ZNK13print_awaiter12await_resumeEv(ptr %awaiter)
; co_return val+1
...
In the learning journey of understanding LLVM IR, it is/was helpful to see
the code generation side-by-side between C++ / LLVM IR (see screenshot below).
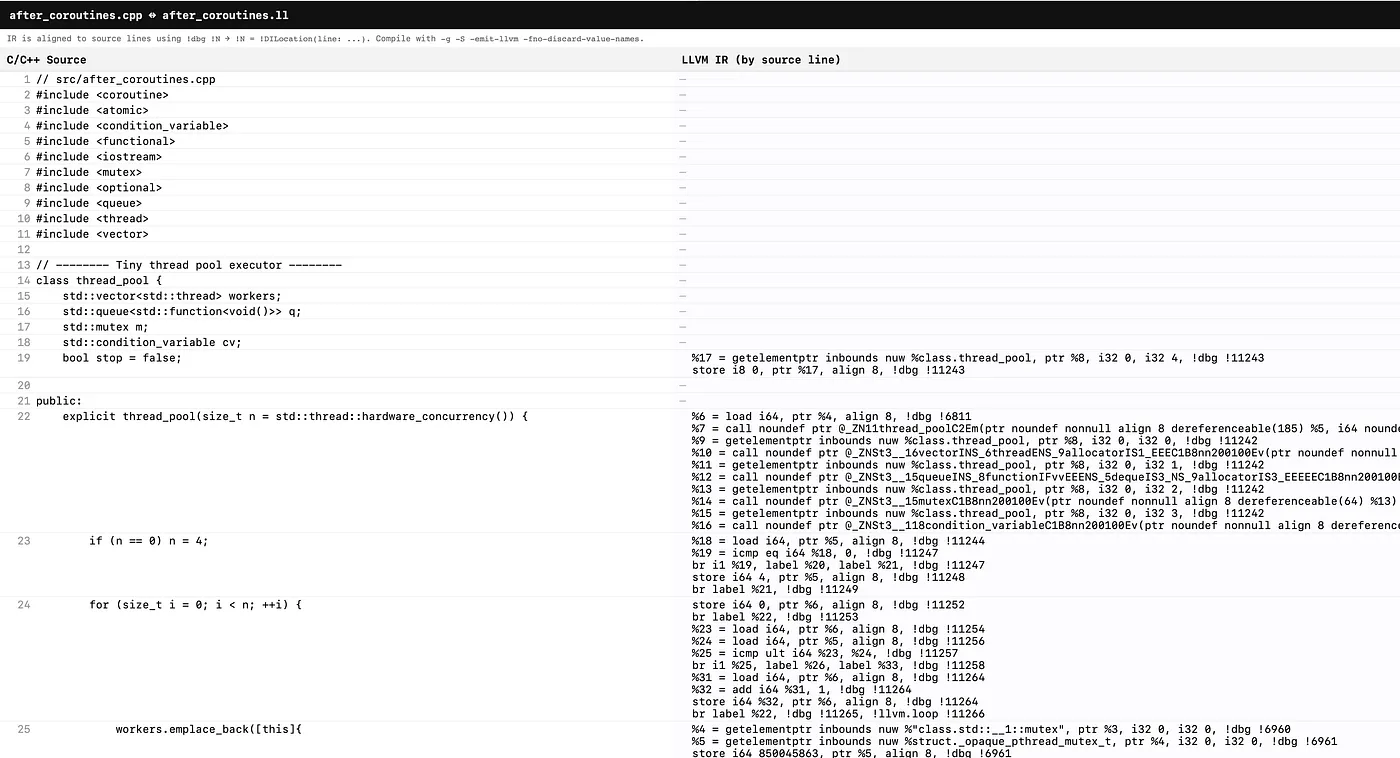
Closing Thoughts
Exploring coroutines at the LLVM IR level is a great way to bridge the gap between language design and compiler internals. If you’re teaching, blogging, or just curious about how modern C++ features work under the hood, try this simplified workflow:
- Write a minimal coroutine.
- Emit raw LLVM IR (“-disable-llvm-passes”).
- Run the coroutine passes manually.
- Compare before vs after.
It’s a hands-on way to demystify what otherwise feels like “magic keywords.”